2026年4月22日,商汤绝影正式发布端侧多模态智能体基座大模型 Sage。Sage 采用 MoE 架构,总参数量为32B,激活参数仅3B ,是行业内首款在车端实现复杂智能体能力的基座大模型,在 PinchBench 上性能领跑全球一线云端大模型,已在英伟达 Orin X 端侧平台实现部署。
AI 全面进入智能体时代,而汽车的复杂智能体能力依赖云端,端侧模型受算力与参数限制,仅能实现简单指令响应。智能座舱因此陷入两难,依赖云端则有延迟与高 Token 成本,坚守端侧则缺失真正智能体能力。Sage 的发布打破这一格局,首次将云端级智能体能力落地端侧。
作为端侧智能体基座,Sage 可接入 OpenClaw、Hermes 等主流 Agent 框架,为更多端侧智能体落地提供核心支撑,可覆盖出行、家庭等全场景。
Sage 的实力,已在国际公开评测中得到印证。在公开 Agent 评测基准 PinchBench 中,Sage 端侧大模型最佳任务完成率达到 94%,超越Claude-Opus-4.6(93.3%)、Claude-Sonnet-4.6(88.0%)、GPT-5.4(90.5%)、Google-Gemini-3(87.0%)、Google-Gemma-4(83.9%)、Qwen3.5-27B(90.0%)、MiniMax-M2.7(89.8%)、MiMo-v2-Pro(87.4%)等国际主流云侧和端侧大模型。
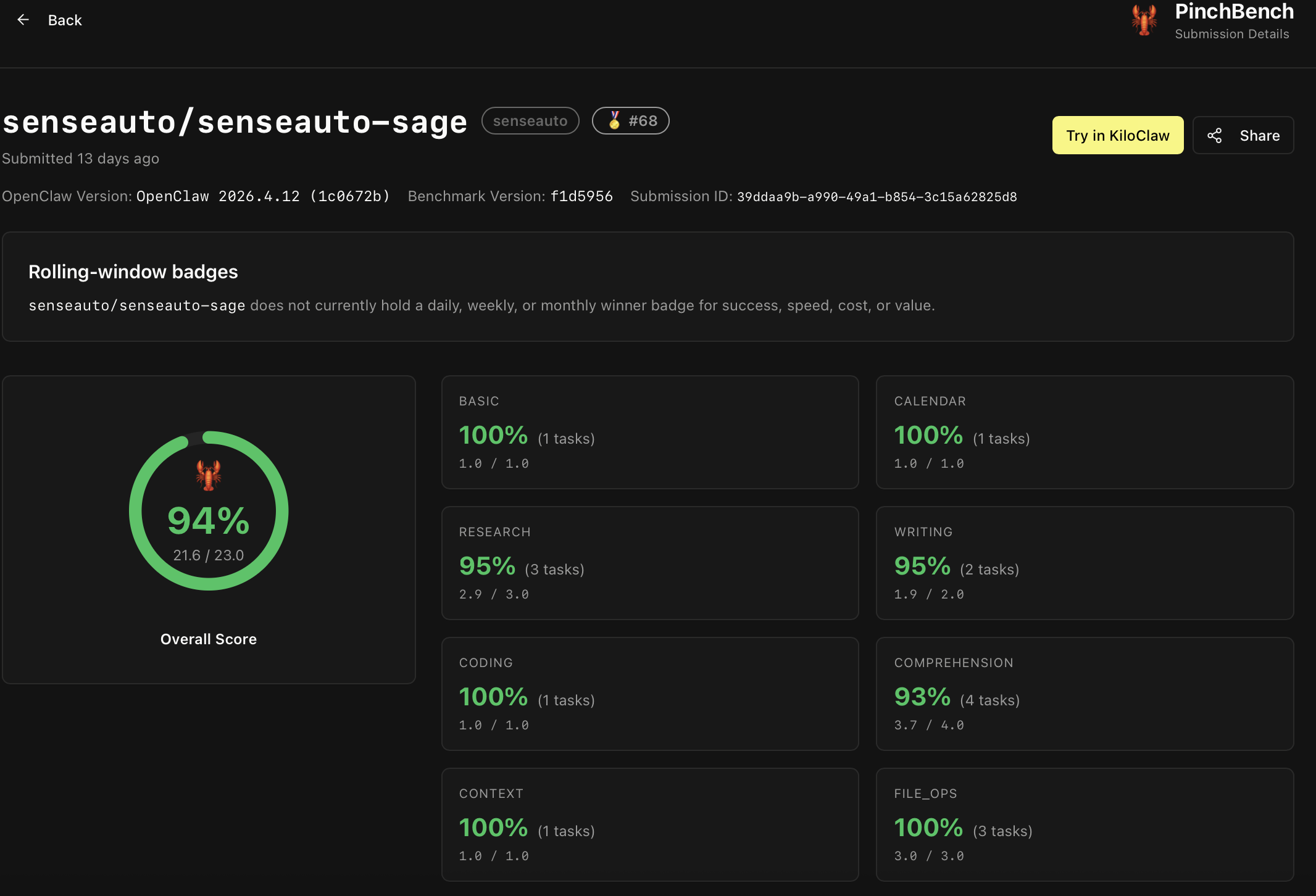
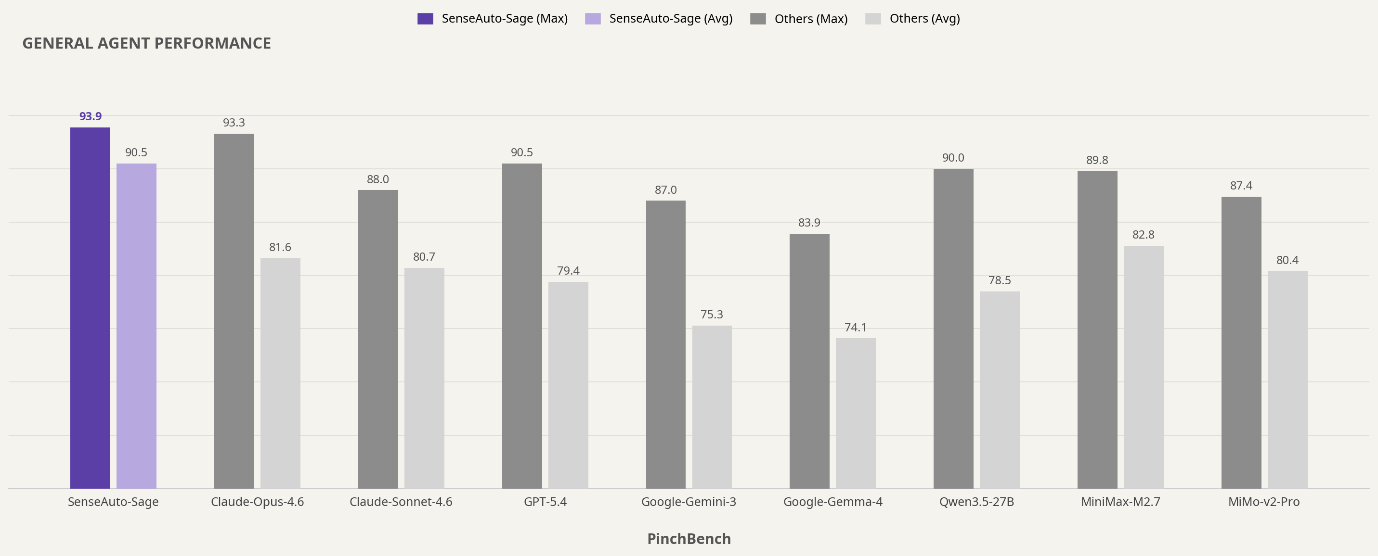
Sage 以仅3B激活的小参数量,超越众多大参数量云侧旗舰,打破 “只有大模型才能做好智能体任务” 的惯性认知,彰显端侧原生技术路线的高效优势。以 小米MiMo-v2-Pro 为例,其激活参数为 42B、总参数规模超 1T,而 Sage 激活参数仅 3B,所需激活算力仅为其 1/14;若按模型权重规模近似估算,显存占用约为其 1/31,但在 PinchBench 上的最佳任务完成率仍高出 6.6 个百分点。
PinchBench 是龙虾之父Peter Steinberger推荐的公开 Agent 评测基准。作为面向真实 Agent工作流的评测榜单,PinchBench 不依赖固定不变的静态题库,而是随着公开任务库持续扩充和版本迭代不断演进。其公开任务库覆盖写作、研究、编码、分析、邮件、文件处理、日程管理、记忆与技能调用等典型场景,重点考察模型在工具调用、多步推理和任务闭环执行中的综合能力。
与此同时,PinchBench 评测要求模型完成真实任务执行,并综合衡量成功率、速度与成本,因此测试周期更长、资源消耗更高,单任务token消耗就可达数十万量级。正因如此,模型在 PinchBench 上取得的精度表现,更能体现其在复杂真实场景中的综合能力与稳定性。
在北京车展期间,商汤绝影将正式推出搭载 Sage 端侧多模态智能体基座大模型的Sage Box,为汽车迈入超级智能体时代筑牢核心根基。
凭借两大黑科技,Sage 让座舱从“听懂指令”到“说到做到”
Sage 端侧大模型在 PinchBench跑赢一众国际主流云/端大模型背后真正的功臣,是商汤绝影围绕 Sage 后训练阶段自研的两项关键技术:SCOUT 和 ERL。
以 SCOUT 和 ERL 为核心的后训练技术体系,一项让模型"学得又快又省",一项让模型"做事不出错",重点突破智能体在学习效率、训练成本和复杂任务稳定执行上的行业挑战,解决了让车载大模型从"能听懂指令"进化到"能独立办成一件复杂的事"的行业公认难题。
SCOUT:让大模型学复杂任务,省 60% 算力
SCOUT(Sub-Scale Collaboration On Unseen Tasks,分级协同学习框架) 技术重点解决大模型学习复杂出行场景任务时成本高、试错慢的问题,在复杂任务能力注入过程中可节省约 60% 的 GPU 小时消耗。
很多任务涉及空间规划、设备联动、多步决策,直接让大模型自己试错学习,既慢又烧算力。SCOUT 的思路是"探路与吸收解耦"——先派一个轻量小模型快速在任务里跑一遍,把走得通的路径筛出来,再把这些高价值经验喂给大模型学习,形成"小模型先探路,大模型再吸收"的学习机制,在降低训练成本的同时,也能够快速掌握更多真实用车场景技能。
(上述技术成果论文已上传arXiv:https://arxiv.org/abs/2601.21754)
ERL:让模型自己擦掉错误步骤,任务成功率提升 20%
已被机器学习顶级会议 ICLR 2026 收录的ERL(Erasable Reinforcement Learning,可擦除强化学习) 技术,聚焦复杂任务链路中的错误识别与纠偏。用户在真实使用中提出的需求,往往需要模型跨多个步骤完成推理和执行,中间一旦某一步出现偏差,整个任务流程就可能失效。
ERL 让模型能够自动识别推理过程中的错误步骤,对错误内容进行擦除并重新生成,从源头阻断偏差扩散,就像给模型装上了"边想边纠错"的能力。这项技术让 Sage 在多跳复杂推理基准上较此前 SOTA 取得显著提升,装车后 Sage 在复杂任务上的完成率提升了 20%。
(上述技术成果论文已上传arXiv:https://arxiv.org/abs/2510.00861)
SCOUT 和 ERL 两项技术前后协同共同推动 Sage 从语言大模型演进为能够独立完成复杂任务的智能体。叠加一体化多模态架构与原生训练数据的优势,Sage 在能力、成本与量产可行性之间取得了平衡,为打造智能体中枢提供了核心 AI 支撑。
端侧跑出全球领先能力,Sage 定义智能上限
如果说 PinchBench 94% 的任务完成率证明了 Sage 能"办成复杂的事",那么真正决定座舱体验的,是模型在各个专业维度上是不是都"够用、够稳、够聪明"。不同能力维度的公开基准上,Sage 全面领先本月最新发布的同量级端侧旗舰模型 Google-Gemma4,把端侧模型的能力天花板抬到了一个新的水位。
MMLU Pro(跨学科专业知识)测试中,Sage 获 76 分,领先同级端侧模型约 10%,证明端侧模型具备云端级通用知识密度;GPQA Diamond(研究生级专业推理)测试中,Sage 获得 77 分,提升 33%,凸显复杂推理深度;Human Semantic Understanding(座舱语义与视觉理解)测试中获 91 分,提升 32%,依托原生数据建立独特优势。
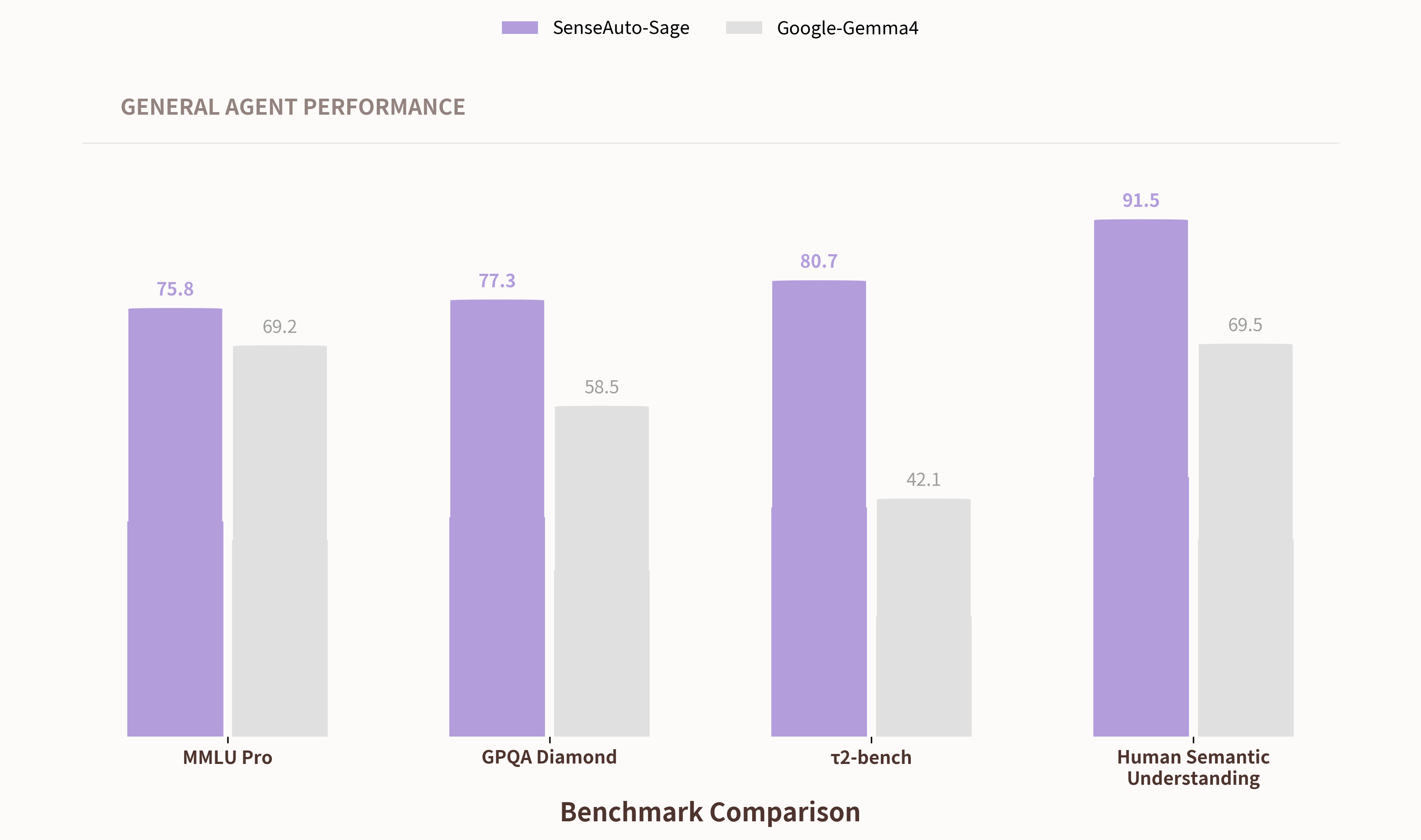
在重点考察任务执行能力的 τ2-bench(工具调用与任务闭环)基准上,Sage 以 80 分的成绩相较 Gemma 4 实现 38% 的提升,接近翻倍领先。这项基准专门评估模型调用工具、走完多步任务的实战能力,也是区分"会聊天的模型"与"会办事的智能体"的关键分水岭。τ2-bench 上近一倍的领先,直接印证了 Sage 作为端侧智能体基座在真实任务执行环节上的绝对优势。
从专业基准到场景体验:Sage 真正"懂场景、会思考、能服务"
这些专业能力落到真实车舱,转化为一组直接影响用户体验的指标:Sage 场景推理精度超过 90%,长链路工具调用、逻辑规划、环境感知任务成功率分别达 92%、89%、94%,复杂指令遵循率提升 40%。
在 Orin X 平台部署下,Sage 可实现首字响应(TTFT)约0.5秒、单 Token 推理延迟(TPOT)低至0.03秒、生成吞吐达到80 tk/S,平均任务时长优于主流API 模型,为座舱智能体提供稳定、实时、可持续在线的运行能力。
模型可以一次性解析用户的复合指令,自动联动空调、影音、导航等车载系统完成任务闭环;结合传感器对乘员状态与路况的感知,还能主动提供儿童模式、智能路线调整等服务。
Sage 不再是"被动唤醒、单次响应"的语音助手,而是一个真正懂场景、会思考、能服务的出行伙伴。
商汤绝影 Sage 端侧多模态智能体基座大模型为舱驾一体方案打通了量产可行的模型路径,打破了技术与落地之间的壁垒,推动智能座舱从基础交互向高阶舱驾融合智能体服务跨越。